In many cases, in file transfers, we want to estimate the remaining time to completion. There are two main routes to go down: either by estimating linearly by remaining # of files (number of files), or linearly by the amount of data left. But both of these cases can lead to very varying estimates over time. We could of course return the maximum amount of time of these two estimates to the user, but I think this is overly conservative.
On a more personal level: I cannot be the only person that has been annoyed at some point at the grossly inaccurate ETA estimations when copying files from one location to another, so I decided to investigate this a bit.
The hypothesis proposed is that a file transfer process consists of two parts:
- transferring the data, and
- creating files.
Transferring actual data is, in this model, assumed to be constant regardless of file size. To this, there is a per-file metadata cost taken up by creating relevant inodes and writing metadata. This is assumed to be a constant time for all files. We can write this model as
ETA(x, N) = x/a + bN
where x is the total data left, N is the number of files left, a is the transfer rate, and b is the per-file overhead.
First I will explain my methodology:
We generate random files from /dev/urandom with the following snippet:
for ((i=1; i<=NUM_FILES; i++)); do
FILE_NAME="$OUTPUT_DIR/file_$i.bin"
head -c "$FILE_SIZE" /dev/urandom > "$FILE_NAME"
done
We then generate files in batches, in the following manner:
- 2097152 files of size 256 bytes,
- 1048576 files of size 512 bytes,
- 524288 files of size 1024 bytes,
- …
- 2 files of size 268435456 bytes.
- 1 file of size 536870912 bytes.
This makes each batch exactly 500 MiB.
We time a copy of each batch to a temporary directory (here located on the same disk, given by mktemp -d), using time cp to measure transfer times. We give the file system a relaxing period (5s) in between cycles, so that waiting file systems operations can finish before next measurement cycle.
When I do this, I see that the “predicted” ETA (using the fitted values for a and b and the actual ETA depends non-linearly on each other. If the hypothesized relation were true, the measurements would be on an affine line.
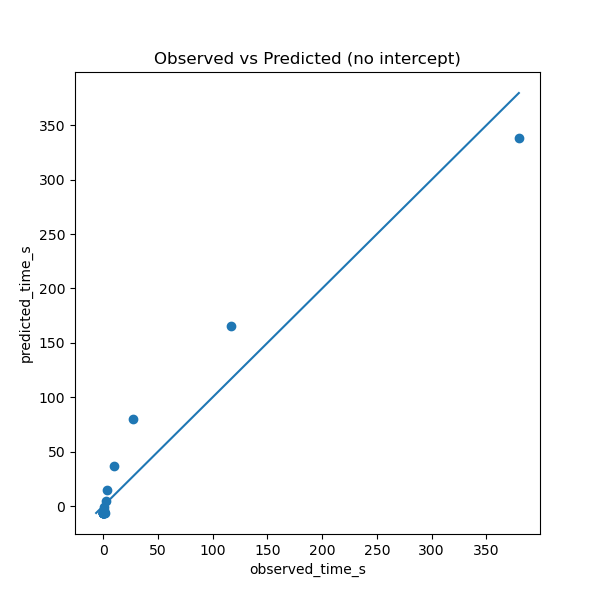
I am curious to why this would be the case. Is file creation not an Θ(1)-operation*, in amortized time? (If relevant, the storage device is an NVMe with a btrfs file system, but I re-created the same results on an ext4 file system on the same storage device).
The second question is tangential: clearly there seems to be a well-defined relationship which is captured by the identified variables (albeit not a bilinear relation). Why are not GUI applications and file managers implementing this sort of model?
* Knuth notation for ”of the same order”
